Model based encodings (2)
In the first segment we looked into how we could make a BPE based encoding, not only based on frequency in the dataset, but directly on the model probability measure of the next token. In that article I mention that dynamic BPE are costly because they stop being a one time operation but have to be done for every batch because the vocabulary might have changed. In this article I try to completely remove the “static” BPE approach and replace it completely with ML blocks.
TL;DR In this article we present an idea to replace classical BPE algorithm with a pure ML version of it.
What is the goal ?
So the goal is to replace BPE algorithm. So it’s go from something like
“T|h|e| |c|a|t| |a|t|e| |t|h|e| |a|p|p|l|e|.”
To something that has less elements :
“The |ca|t |at|e |the| |app|le|.”
In one sentence, BPE fuses bytes to form tokens based on frequency in the full dataset. For a more detailed example, look that the previous article. In this example, you can see there is always a split after a space. That’s a limitation of BPE so actually our target might look different, maybe more like
“The cat |at|e |the app|le|.”
Here we can notice that “The cat” is a full token and contain 2 actual words. So the goal is to fuse some starting bytes into N tokens (let’s say ~10k) that hopefully capture regularities in our dataset and are at least correlated to frequency in the original dataset like BPE was.
Another property we need to have from BPE is that it can encode an arbitrary string of text. It does not matter if it’s not the same language or even if it makes sense, you CAN encode it, that is a very desirable property. It avoids the out-of-vocabulary problem.
Approach
Tokenization
So let’s imagine we have a trained transformer like GPT-2. But trained on bytes directly NOT on tokens like the original transformer. Now we can use the idea that when a model is highly confident, it probably means that what it’s about to predict is “in the same token”. Let’s take an example. Try to predict the following Character (as in a single letter) in the next 2 sentences
Sentence 1: “Who are yo…”
Sentence 2 : “I like …”
In the first sentence, normally you would vote with very high confidence for “u”, whereas in the second sentence, you lack a lot of context to be exactly sure on what’s coming next. So “you” would be a token, whereas “like …” can’t be a single token, it has to be at least 2, “like “ and “…”.
Here is a small gif of actual probabilities of the language model on a small sentence
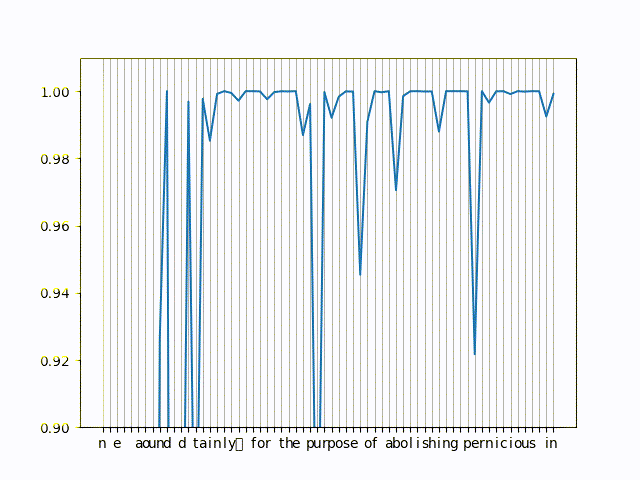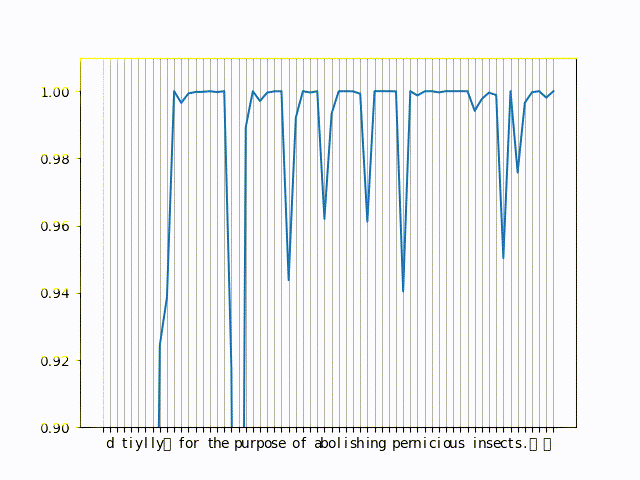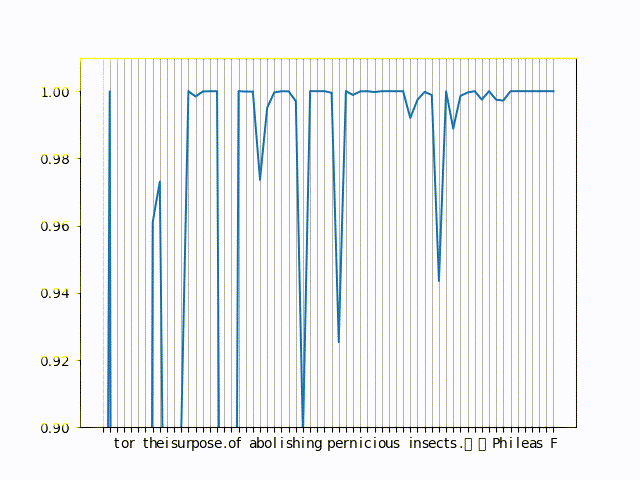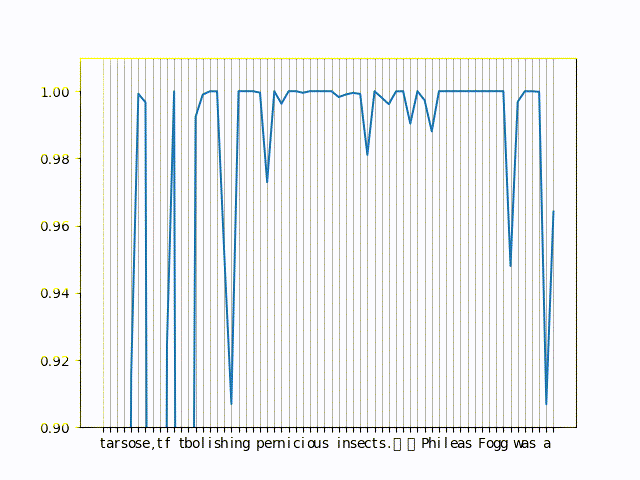
You can see the in the left of the graph the probabilities drop, those are the tokens that try to get predicted but are missing context (because we have very few characters before them. For the right side, you can see the drops in probability are pretty consistent and correspond to word boundaries most often.
Handling unknown tokens
Now we know how we are going to “fuse” characters, but we are not done yet. BPE tokens are a discrete SET of identified values from 0 to N (~10k in this experiment). Also BPE can encode an arbitrary new string by using it’s fusion table. So we can’t just run our algorithm on some specific dataset, count all the tokens created and declare that these are the N tokens for eternity. Let’s imagine I feed my algorithm a new sentence, in a different language, French for instance.
“J’adore l’Italie.”
We can run our “tokenizer” on this, and receive something like this
“J|’|ado|re |l’|Ita|lie.”
Now “ado” might not be in our original list, so what do we do with it ? Do we declare the token wrong and split it ? That would be odd.
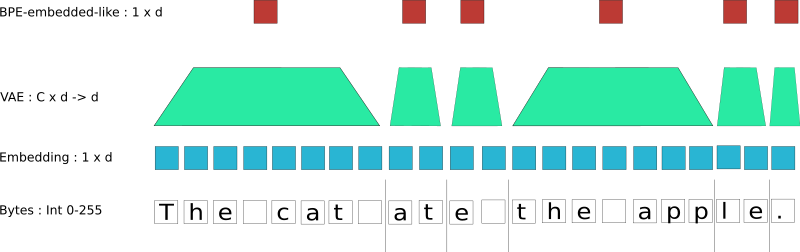
A key insight, is to remember that the first step of the discrete “token” once it enters the model (all of them do that, it’s really not specific to transformer or GPT-2) it gets embedded, meaning we go from a number between 1 and N, to a vector in d dimension space (d is between 100 and 1000 generally).
For instance token 3 gets mapped to [0.3, -0.15, 1.4, …] while token 4 gets mapped to [-2.4, -0.014, 0.45, …]
So the idea it to generate directly a token embedding (a vector in d-dimension), not necessarily a discrete value (a number between 0 and vocabulary size).
In order to do that we need that all tokens should now be represented in the same way by a d dimension space vector. One way to achieve that is to use an autoencoder.
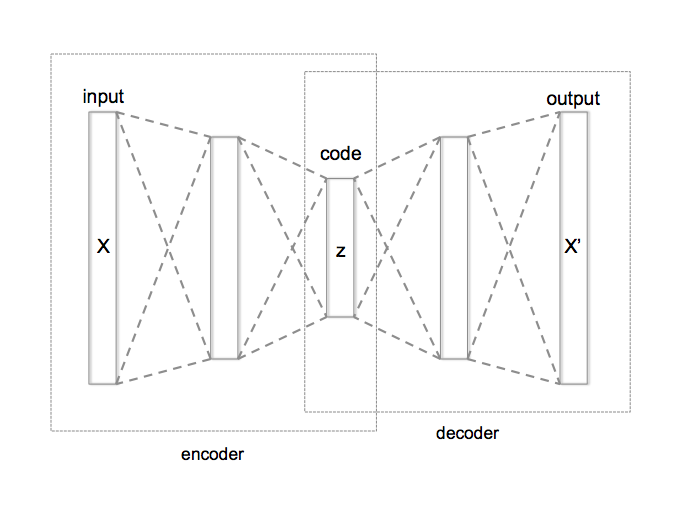 or with code
or with code
The core idea is that when we encounter a new unseen token like “ado” it will still have a representation through the VAE, and will probably be close to a known token like “add”. This can help the network overcome odd tokenization or spelling errors.
## The name is VAE but I didn't use the internal KL loss in the end as it prevented/slowed down the learning.
class VAE(nn.Module):
def __init__(self):
super(VAE, self).__init__()
self.M = config.CONTEXT_SIZE * config.EMBEDDING_DIM
layer = nn.Linear
m = 400
self.fc1 = layer(self.M, m)
self.fc21 = layer(m, config.EMBEDDING_DIM)
self.fc22 = layer(m, config.EMBEDDING_DIM)
self.fc3 = layer(config.EMBEDDING_DIM, m)
self.fc4 = layer(m, self.M)
def encode(self, x):
# x is [Batch, Context size, Embedding dim]
x = x.view(-1, self.M)
h1 = F.relu(self.fc1(x))
return self.fc21(h1), self.fc22(h1)
def reparameterize(self, mu, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return mu + eps * std
def decode(self, z):
h3 = F.relu(self.fc3(z))
return torch.tanh(
self.fc4(h3).view(-1, config.CONTEXT_SIZE, config.EMBEDDING_DIM)
)
def forward(self, x):
mu, logvar = self.encode(x)
z = self.reparameterize(mu, logvar)
return mu, logvar, z, self.decode(z)
Final network
Results
Here is a summary of the values of the tokenization we got.
| Raw | BPE | Model based | |
|---|---|---|---|
| Vocabulary size | 256 | 10000 | 26262 |
| #Tokens | 387k | 90k | 92k |
| Avg token length | 1 | 3.3 | 6.65 |
Here is a excerpt of the kind of tokenization we created
|He w|as on|e of| the |most |n|oticea|ble member|s of the| Reform| Club|, |th|ough| he| s|eemed |always |to |avoid |att|racting at|tention|; an en|ig|mat|i|cal |p|erson|age|,| |ab|out whom l|ittle| was |known|, |e|xc|ept that |he| w|as |a |poli|shed m|an| o|f |th|e |wo|rld|. |Pe|ople sa|id| that h|e |re|sembl|ed| |Byron|--at least| t|hat |his hea|d w|as |Byronic|; |but| he was |a |b|earde|d, tranquil| Byron|, who| |might live| on a |thousand year|s |w|ithout g|r|owing o|ld|.| |Certainly| an| English|man|, it |was |m|ore |doubt|ful w|h|ether |Phileas Fogg| w|as |a |London|er|.
This version has been done with epsilon=0.0015.
As you can see, “Phileas Fogg” is already a token in this situation, which is a multi-word token not achievable by regular BPE. You can also see, a lot of words contain only single bytes tokens which is why this method compresses LESS than regular BPE at the same vocabulary size. Another note is that classical words like “was” is already a token (in the last sentence) but it’s not always the case, this token is context dependent now !
VAE
After the VAE step, the reconstruction is not perfect yet perfectly legible.
|He w|as on|e of| the |most |n|oticea|ihe member|s of the| reform| Club|, |th|ough| he| s|eemed |always |to |asoid |att|nacting at|tention|, an en|ig|mat|i|cal |p|erson|age|,| |ab| it whom l|ittle| was | nown|, |e|xc| pt that |he| w|as |a |poli|shed m|an| o|f |th|e |wo|rld|. |Pe|ople sa|id| that h|e |re|sembl|ed| |pyron| cat least| t|hat |has hea|d w|as |blronic|; |but| he was |a |b|earde|in tranquil| pyron| who| |eight live| on a |dar and year|s |w|ithout g|r|owing o|ld|.| |rertainly| an| English|man|, it |was |m|ore |doubt|ful w|h|ether |Phileas Fogg| w|as |a |London|er|.
Most of the errors tend to lie in the first characters of long tokens.That’s because, I’m forced to padd the input of the VAE and to mask that padding. In practice that means that the first characters of long tokens get updated less that the others so necessarily they contain more errors. More information.
Upper level
In order to complete the experiment, we need to check that the original language model done directly at BPE level can be done with this new model-based BPE encoding.
It’s pretty slow to train that upper level because we need to flow the gradients all the way through the VAE decoder, and the lower layer decoding step, in order to get the character level loss (softmax + nll_loss) to properly train something. That’s a limit of the current approach.
If we randomly split the text into train&validation, we can learn almost perfectly (97% top-1 character level accuracy) the language model on top of that Model based BPE.
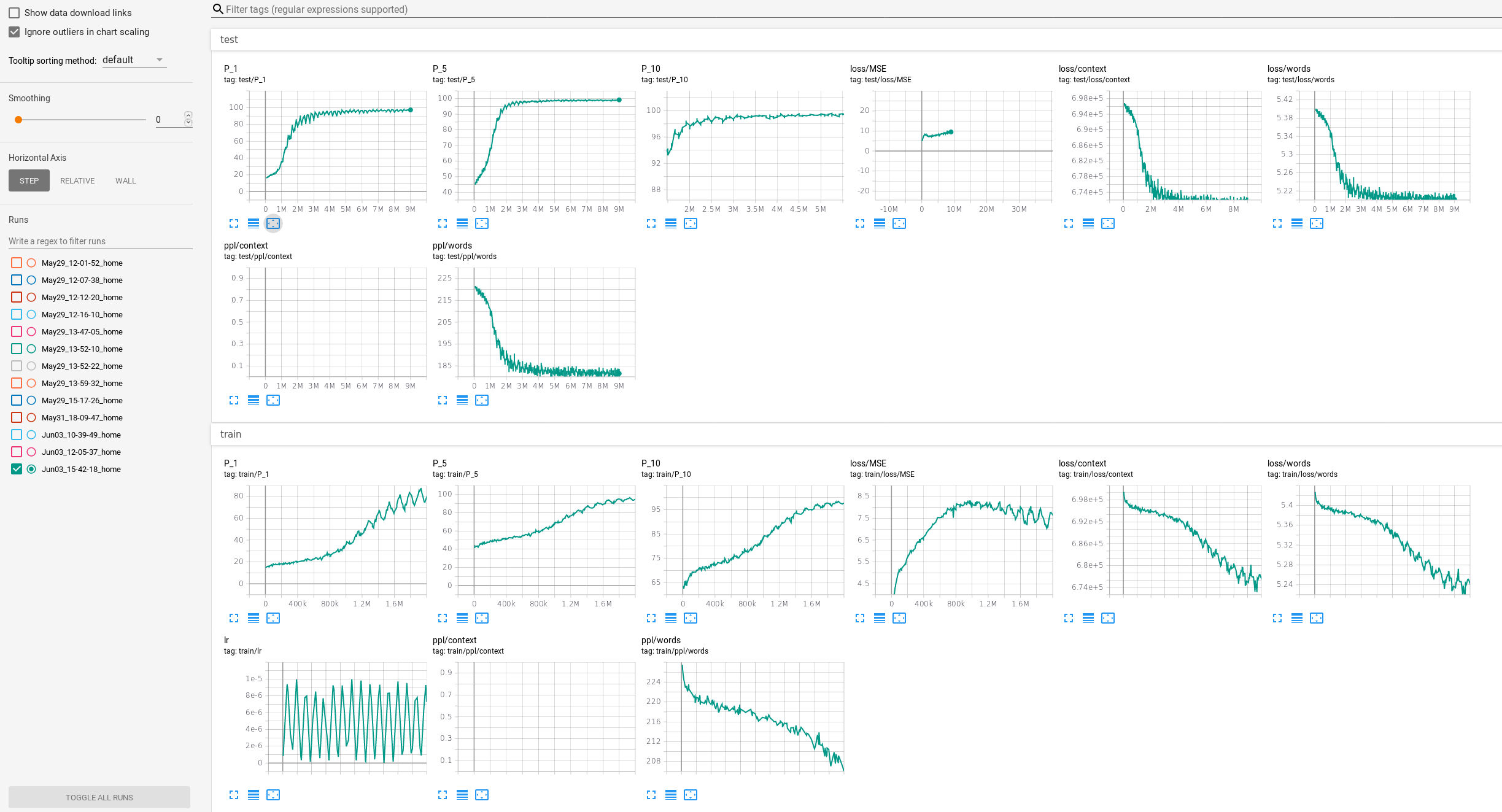
However this can be considered overfitting because even though a specific input was never seen in the valid set, a very close one was.
If instead we try to compare with a fixed split, where the last part of the book is considered the valid set, then we get much lower result.
We could achieve 25% exact character matching, and ~77% top-10 character matching on the valid set, which is the end of the book ! The same results happen with BPE, even worse ! we can’t get past 13% top-1 and 25% top-10 on the regular BPE. That’s understandable because the dataset is very small and the last part of the book is different so it’s very hard to infer it from just the beginning and no other text.
Another note, is that model based BPE are not tokenizing deterministicly, there is some variance to it, depending on the context of a particular word. This actually seems to be a good property (See this) and might explain away the better performance of model based BPE over regular BPE. Keep in mind it’s 25% of the characters that are correct. If we looked at a discrete view of tokens we probably would have a much higher prediction rate (it’s left for future work for now).
Here is a picture from the tensorboard values, P_1 is probability that the character predicted is the correct one, P_10 is that it is in the top-10 values.
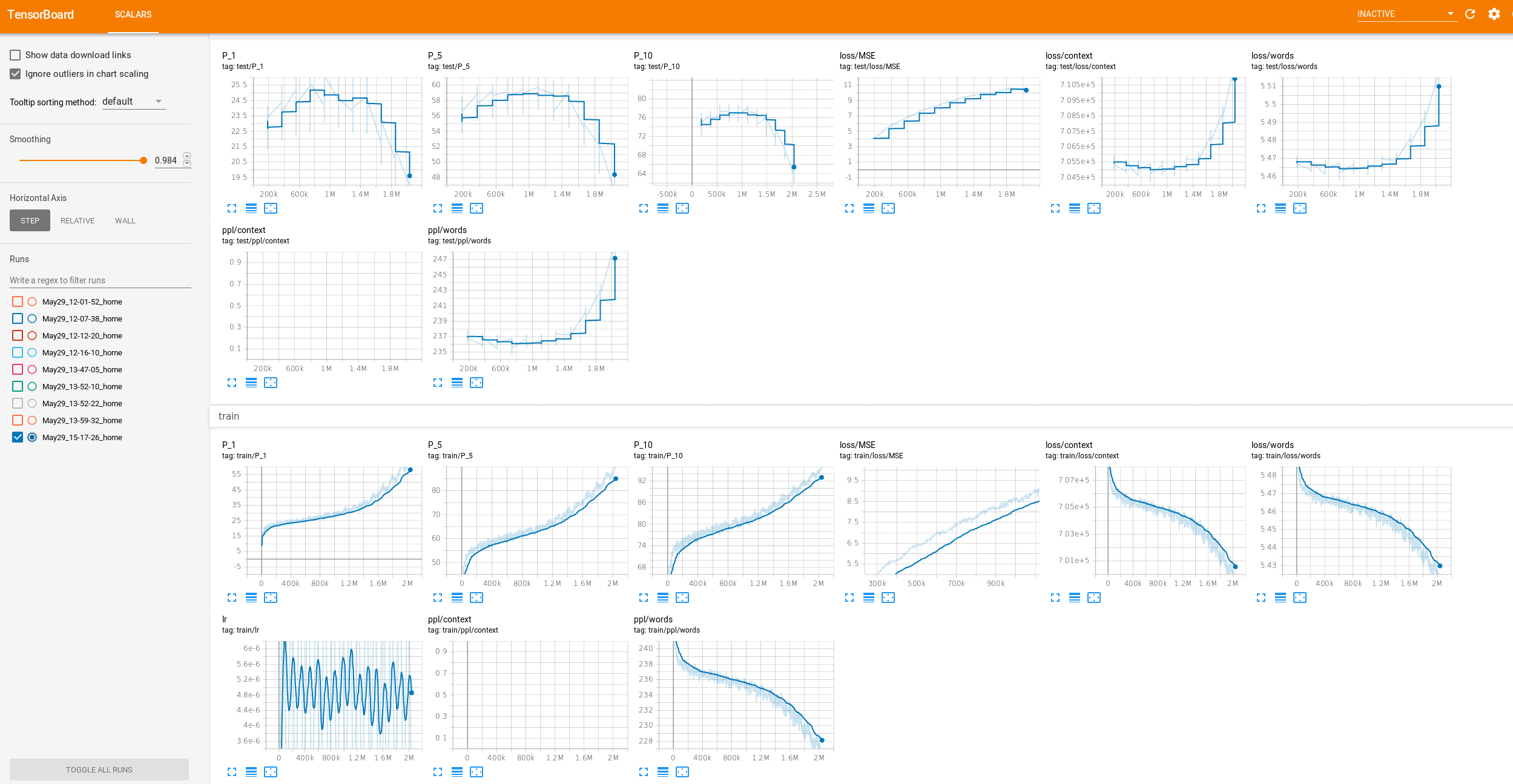
The overfitting starts happening around the ~1M steps mark.
Notes
- In the experiment we learned model by model, freezing the lower model before training something on top. It’s because the batching of different layers occur differently. Learning the whole thing end-to-end is probably going to need some thought. The batching is easy for the lower level, every batch needs a tensor of shape CONTEXT_SIZE (=64) of [0-255] ints. For the VAE, we need to have a variable length (depending on the length token) times EMBEDDING_DIM (=128). The upper level needs only tensors of size CONTEXT_SIZE * EMBEDDING_DIM yet if we want to try and end-to-end training, we have no idea how many bytes we need to generate 1 correct tensor in the upper layer. We know it’s no more than CONTEXT_SIZE² but that would be prohibitive to use that value.
- The loss NEEDS to always be the byte-level nll loss. At first I thought a simple MSE loss in the embedding space could be enough to learn the proper models. It seems to not be the case. I could only achieve meaningful results by always referring to the original strings and calculating the NLL Loss. When using this loss, the MSE actually increases. This leads me to think that encoding/decoding + softmax are highly anisotropic operators. Looking at the singular values of the embedding matrix, we can see that the highest one is 7.35, the lowest one 0.12, so there are 2 orders of magnitude between the 2. This anisotropy means that the MSE loss which considers all dimensions of the embeddding equal is actually couting way too much some irrelevant dimensions. It would be much faster and simpler if we could train directly on MSE (it would enable us to train without running all the decoding steps to generate the loss). So we need to add some spectral loss on the embedding on the lower language model to test that hypothesis.
- The tokens have variable lengths. In order to fix this, we have to padd all sequences during learning. Because we padd, we have to mask the padding during training for both VAE and upper LM. Keeping track of this is pretty nifty and it means gradients on rarely used places will rarely get updated. So we will almost surely miss some letters in our tokens. Either at the front or the end of the token depending on how we padd the tokens.
Future work
- Actually testing discretizing the tokens to compare with the regular BPE. In that direction, also comparing with a randomized tokenizer as used in SentencePiece to make sure the results are actually comparable and are indeed linked to tokenization variance.
- The masking problem really seems to be a current limit of the model. Finding a workaround would be really valuable.
- The fact that the NLL loss is required slows down upper layers. It would be awesome if we could smooth out the encoding/decoding matrix so that L2 directly for VAE and the upper layer works. It probably goes against regular language model embedding so not sure it’s doable.
- Making the epsilon based tokenization directly after the embedding layer. This would help stack those levels hopefully learning higher and higer representations of text leading the sentence embedding and so on.
- On the same idea, another direction would be to do actual discrete tokenization to allow for the models to stack.